
歡迎閱讀我們關(guān)于使用 Ollama 運行 Qwen2:7b 的教程。在本指南中,我們將使用捷智算平臺提供的我們最喜歡的 GPU 之一 A5000,您會很高興發(fā)現(xiàn)該型號在性能上如何超越 Mistral 和 Llama3。
A5000由 NVIDIA 提供支持,基于安培架構(gòu),是一款功能強大的 GPU,可以增強渲染、圖形、AI 和計算工作負載的性能。A5000 提供 8192 個 CUDA 核心和 24 GB GDDR6 內(nèi)存,提供卓越的計算能力和內(nèi)存帶寬。
A5000 支持實時光線追蹤、AI 增強型工作流程以及 NVIDIA 的 CUDA 和 Tensor 核心等高級功能,可提高性能。憑借其強大的功能,A5000 非常適合處理復雜的模擬、大規(guī)模數(shù)據(jù)分析和渲染高分辨率圖形。
Qwen2-7b 是什么?
Qwen2 是最新推出的大型語言模型系列,提供基礎(chǔ)模型和指令調(diào)優(yōu)版本,參數(shù)范圍從 5 億到 720 億,其中包括一個 Mixture-of-Experts 模型。該模型最棒的地方是它在 Hugging Face 上開源了。
與 Qwen1.5 等其他開源模型相比,Qwen2 在語言理解、生成、多語言能力、編碼、數(shù)學和推理等各種基準測試中均表現(xiàn)優(yōu)異。Qwen2 系列基于Transformer架構(gòu),并進行了 SwiGLU 激活、注意 QKV 偏差、組查詢注意和改進的標記器等增強功能,可適應(yīng)多種語言和代碼。
此外,據(jù)說 Qwen2-72B 在所有測試基準中的表現(xiàn)都遠遠優(yōu)于 Meta 的Llama3-70B 。
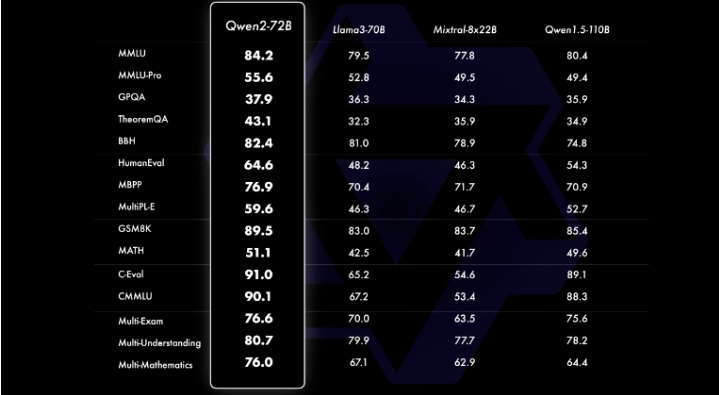
Qwen 性能比較
下圖顯示了 Qwen2-72B-Instruct 在各個領(lǐng)域的不同基準測試中的綜合評估。該模型在增強能力和符合人類價值觀之間取得了平衡。此外,該模型在所有基準測試中的表現(xiàn)都顯著優(yōu)于 Qwen1.5-72B-Chat,與 Llama-3-70B-Instruct 相比也表現(xiàn)出了競爭力。即使是較小的 Qwen2 模型也超越了類似或更大尺寸的最先進的模型。Qwen2-7B-Instruct 在各個基準測試中保持優(yōu)勢,尤其是在編碼和中文相關(guān)指標方面表現(xiàn)出色。
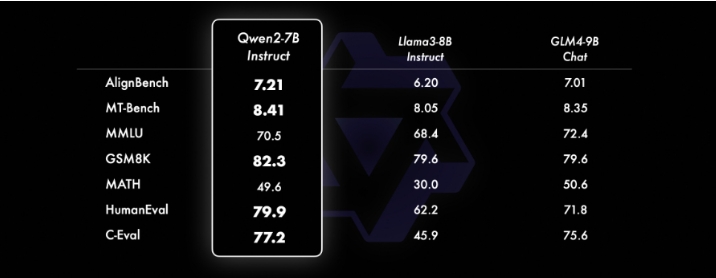
Qwen 性能比較
可用型號
Qwen2 在包含英語和中文等 29 種語言的數(shù)據(jù)集上進行訓練,有 5 種參數(shù)大小:0.5B、1.5B、7B、57B 和 72B。7B 和 72B 模型的上下文長度已擴展至 128k 個 token。
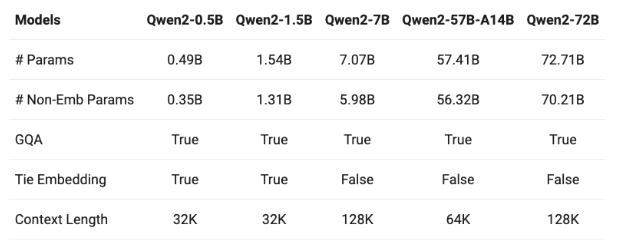
Qwen2 系列包括五種不同尺寸的基礎(chǔ)模型和指令調(diào)整模型
Ollama簡介
本文將向您展示使用 Ollama 運行 Qwen2 的最簡單方法。Ollama 是一個開源項目,它提供了一個用戶友好的平臺,用于在您的個人計算機上或使用捷智算平臺等平臺執(zhí)行大型語言模型 (LLM)。
Ollama 提供對各種預訓練模型庫的訪問,可在不同的操作系統(tǒng)上輕松安裝和設(shè)置,并公開本地 API 以無縫集成到應(yīng)用程序和工作流程中。用戶可以自定義和微調(diào) LLM,通過硬件加速優(yōu)化性能,并受益于交互式用戶界面以實現(xiàn)直觀的交互。
使用 Ollama 在捷智算平臺上運行 Qwen2-7b
在開始之前,讓我們先檢查一下 GPU 規(guī)格。
nvidia-smi
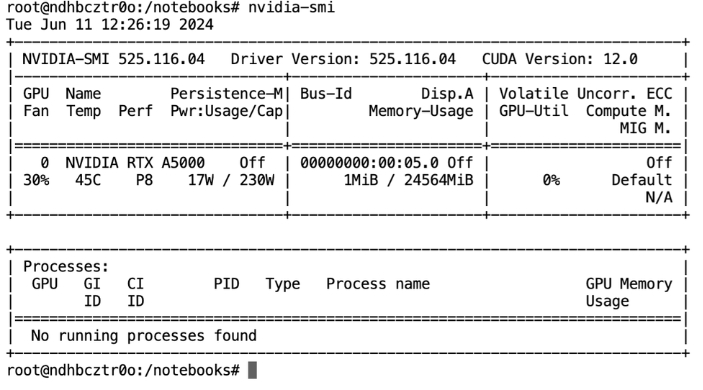
顯示 NVIDIA A5000 規(guī)格
接下來,打開一個終端,我們將開始下載 Ollama。要下載 Ollama,請將以下代碼粘貼到終端中,然后按 Enter。
curl -fsSL https://ollama.com/install.sh | sh

這行代碼將開始下載 Ollama。
完成后,清除屏幕,鍵入以下命令,然后按回車鍵運行模型。
ollama run qwen2:7b
如果出現(xiàn)錯誤:無法連接到 ollama 應(yīng)用程序,它是否正在運行?嘗試運行以下代碼,這將有助于啟動 ollama 服務(wù)
ollama serve
并打開另一個終端并再次嘗試該命令。
或者嘗試通過運行以下命令手動啟用 systemctl 服務(wù)。
sudo systemctl enable ollama
sudo systemctl start ollama
現(xiàn)在,我們可以運行模型進行推理。
ollama run qwen2:7b
這將下載模型的各個層,另外請注意這是一個量化模型。因此下載過程不會花費太多時間。
接下來,我們將開始使用我們的模型來回答一些問題并檢查模型如何工作。
為斐波那契數(shù)列編寫一個 Python 代碼。

Qwen2:7b 模型生成的斐波那契的 Python 代碼
請隨意嘗試其他型號版本,但 7b 是最新版本且可與 Ollama 一起使用。
該模型在各方面都表現(xiàn)出了令人印象深刻的性能,與早期模型相比,整體性能與 GPT 相當。
測試數(shù)據(jù)來自 Jailbreak,并翻譯成多種語言,用于評估。值得注意的是,Llama-3 在多語言提示下表現(xiàn)不佳,因此被排除在比較之外。研究結(jié)果表明,Qwen2-72B-Instruct 模型達到了與 GPT-4 相當?shù)陌踩剑⑶腋鶕?jù)顯著性檢驗(P 值),其表現(xiàn)明顯優(yōu)于Mistral-8x22B模型。
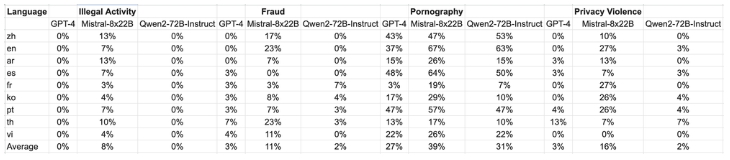
大型模型在四類多語言不安全查詢中產(chǎn)生的有害響應(yīng)發(fā)生情況:非法活動、欺詐、色情和隱私暴力
結(jié)論
總之,我們可以說 Qwen2-72B-Instruct 模型在各種基準測試中都表現(xiàn)出色。值得注意的是,Qwen2-72B-Instruct 超越了之前的迭代,例如 Qwen1.5-72B-Chat,甚至可以與 GPT-4 等最先進的模型相媲美,這從顯著性測試結(jié)果中可以看出。此外,它的表現(xiàn)明顯優(yōu)于 Mistral-8x22B 等模型,凸顯了其在確保多語言環(huán)境中的安全性方面的有效性。
展望未來,Qwen2 等大型語言模型的使用量迅速增長,預示著未來人工智能驅(qū)動的應(yīng)用和解決方案將變得越來越復雜。這些模型有可能徹底改變各個領(lǐng)域,包括自然語言理解、生成、多語言交流、編碼、數(shù)學和推理。隨著這些模型的不斷進步和完善,我們可以預見人工智能技術(shù)將取得更大的進步,從而開發(fā)出更智能、更像人類的系統(tǒng),更好地滿足社會需求,同時遵守道德和安全標準。











