
隨著構(gòu)建生成式 AI 變得越來越主流,有兩種 NVIDIA GPU 型號(hào)已成為每個(gè) AI 構(gòu)建者基礎(chǔ)設(shè)施愿望清單的首選——H100 和 A100。H100 于 2022 年發(fā)布,是目前市場(chǎng)上功能最強(qiáng)大的顯卡。A100 可能較舊,但仍然很熟悉、可靠且功能強(qiáng)大,足以處理要求苛刻的 AI 工作負(fù)載。
關(guān)于單個(gè) GPU 規(guī)格的信息很多,但我們不斷聽到客戶說他們?nèi)匀徊淮_定哪種 GPU 最適合他們的工作量和預(yù)算。H100 表面上看起來更貴,但它們能通過更快地執(zhí)行任務(wù)來節(jié)省更多錢嗎?
A100 和 H100 具有相同的內(nèi)存大小,那么它們最大的區(qū)別在哪里?通過這篇文章,我們希望幫助您了解當(dāng)前用于 ML 訓(xùn)練和推理的主要 GPU(H100 與 A100)之間需要注意的主要區(qū)別。
技術(shù)概述
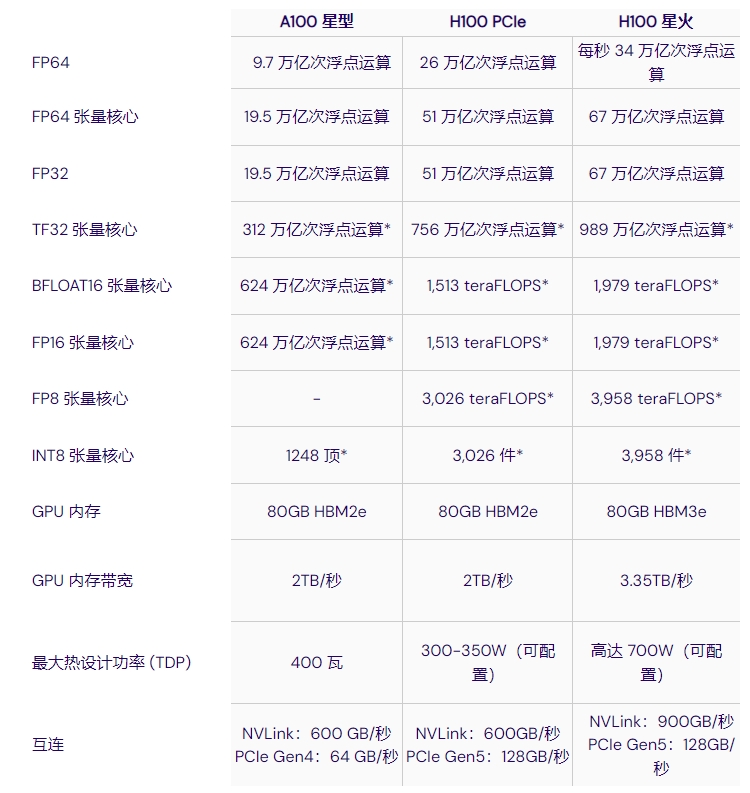
表 1 - NVIDIA A100 與 H100 的技術(shù)規(guī)格
據(jù) NVIDIA 介紹,H100 的推理性能最高可提高 30 倍,訓(xùn)練性能最高可提高 9 倍。這得益于更高的 GPU 內(nèi)存帶寬、升級(jí)的 NVLink(帶寬高達(dá) 900 GB/s)和更高的計(jì)算性能,H100 的每秒浮點(diǎn)運(yùn)算次數(shù) (FLOPS) 比 A100 高出 3 倍以上。
Tensor Cores:與 A100 相比,H100 上的新型第四代 Tensor Cores 芯片間速度最高可提高 6 倍,包括每個(gè)流多處理器 (SM) 加速(2 倍矩陣乘法-累積)、額外的 SM 數(shù)量和更高的 H100 時(shí)鐘頻率。值得一提的是,H100 Tensor Cores 支持 8 位浮動(dòng) FP8 輸入,可大幅提高該精度的速度。
內(nèi)存: H100 SXM 具有 HBM3 內(nèi)存,與 A100 相比,帶寬增加了近 2 倍。H100 SXM5 GPU 是世界上第一款具有 HBM3 內(nèi)存的 GPU,可提供 3+ TB/秒的內(nèi)存帶寬。A100 和 H100 都具有高達(dá) 80GB 的 GPU 內(nèi)存。
NVLink: H100 SXM 中的第四代 NVIDIA NVLink 比上一代 NVLink 的帶寬增加了 50%,多 GPU IO 的總帶寬為 900 GB/秒,運(yùn)行帶寬是 PCIe Gen 5 的 7 倍。
性能基準(zhǔn)
在 H100 發(fā)布時(shí),NVIDIA 聲稱 H100 可以“與上一代 A100 相比,在大型語言模型上提供高達(dá) 9 倍的 AI 訓(xùn)練速度和高達(dá) 30 倍的 AI 推理速度”。根據(jù)他們自己發(fā)布的數(shù)據(jù)和測(cè)試,情況確實(shí)如此。然而,測(cè)試模型的選擇和測(cè)試參數(shù)(即大小和批次)對(duì) H100 更有利,因此我們需要謹(jǐn)慎對(duì)待這些數(shù)據(jù)。
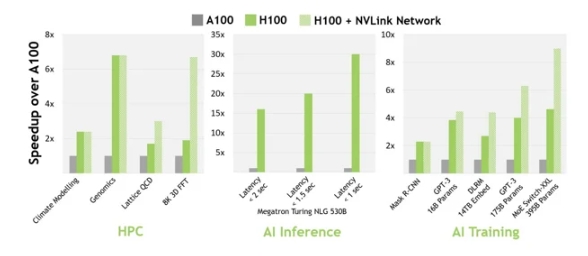
NVIDIA基準(zhǔn)測(cè)試 - NVIDIA H100 與 A100
其他來源也進(jìn)行了基準(zhǔn)測(cè)試,結(jié)果表明 H100 的訓(xùn)練速度比 A100 快 3 倍左右。例如,MosaicML 在語言模型上進(jìn)行了一系列具有不同參數(shù)數(shù)量的測(cè)試,發(fā)現(xiàn)以下情況:
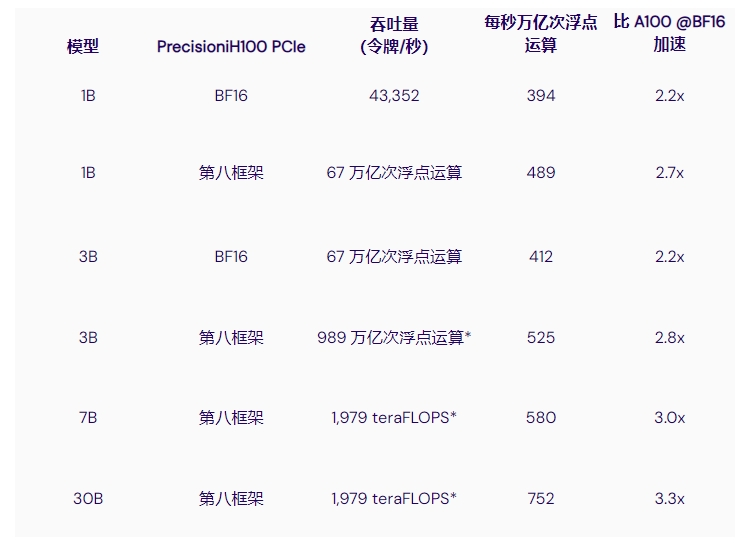
MosaicML基準(zhǔn)測(cè)試 - NVIDIA H100 與 A100
LambaLabs 嘗試使用 FlashAttention2 訓(xùn)練大型語言模型(具有 175B 個(gè)參數(shù)的類 GPT3 模型)對(duì)兩種 GPU 進(jìn)行基準(zhǔn)測(cè)試時(shí),獲得的改進(jìn)較少。在這種情況下,H100 的性能比 A100 高出約 2.1 倍。
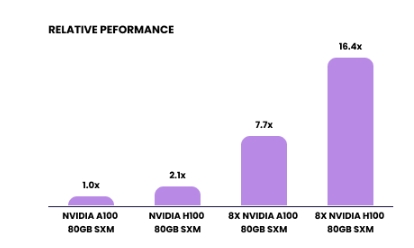
175B LLM 上的 FlashAttention2 培訓(xùn)
雖然這些基準(zhǔn)測(cè)試提供了有價(jià)值的性能數(shù)據(jù),但這并不是唯一的考慮因素。將 GPU 與手頭的特定 AI 任務(wù)相匹配至關(guān)重要。此外,還必須將總體成本納入決策之中,以確保所選 GPU 能夠?yàn)槠漕A(yù)期用途提供最佳價(jià)值和效率。
成本和性能考慮
性能基準(zhǔn)測(cè)試顯示 H100 領(lǐng)先,但從財(cái)務(wù)角度來看這合理嗎?畢竟,在大多數(shù)云提供商中,H100 通常比 A100 更貴。
為了更好地了解 H100 是否值得增加成本,我們可以使用 MosaicML 的工作,該工作估算了在 134B 個(gè) token 上訓(xùn)練 7B 參數(shù) LLM 所需的時(shí)間
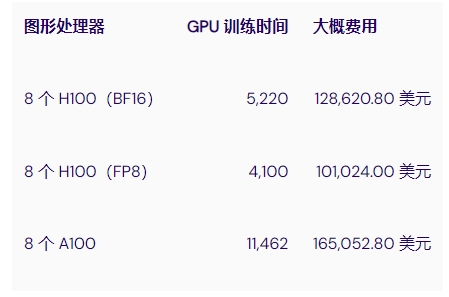
175B LLM 上的 FlashAttention2 培訓(xùn)
如果我們考慮捷智算平臺(tái)對(duì)這些 GPU 的定價(jià),我們可以看到在一組 H100 上訓(xùn)練這樣的模型可以節(jié)省高達(dá) 39% 的成本,并且訓(xùn)練時(shí)間可以減少 64%。當(dāng)然,這種比較主要與 FP8 精度的 LLM 訓(xùn)練有關(guān),可能不適用于其他深度學(xué)習(xí)或 HPC 用例。
展望 GH200
2024 年,我們將看到 NVIDIA H200 的廣泛可用性,它擁有更大的內(nèi)存和更高的帶寬(高達(dá) 4.8 TB/s),據(jù)說推理能力比 H100 提高了 1.6 倍到 1.9 倍。未來,我們將對(duì)這款產(chǎn)品和 L40(看起來更適合 ML 生命周期的推理部分)進(jìn)行未來分析。敬請(qǐng)期待!
開始使用捷智算平臺(tái)
進(jìn)入捷智算平臺(tái)官網(wǎng),即可訪問并按需租賃 H100、A100 和更多 GPU。或者,聯(lián)系我們,我們可以幫助您設(shè)置滿足您所有需求的私有 GPU 集群。











